
This is the fourth and final in a series of four original Blog posts; the first is HERE the second is HERE the third is HERE. [Ed.]
By Matti Pohjonen
The previous cluster of methods looked at in the blog post series included methods developed to extrapolate insight from the content produced online and on social media. It argued that one of the major challenges of analysing extremist content had to do with the ambiguity of human communication, which can make the accurate classification and analysis of content difficult. One way to mitigate this problem is to carefully curate the datasets used both for their validity but also to avoid replicating latent biases in large-scale datasets.
The final cluster of methods looked at in this blog series focuses on approaches that have been used to predict extremist behaviour from online and social media data. Given the growing ubiquity of machine- and deep-learning-based approaches in computational research, these commonly involve methods whose aim is not only to describe the data but also to infer patterns from the data that can potentially help predict future behaviour. Guzik defined these approaches as “the application of database technology and techniques – such as statistical analysis and modelling – to uncover hidden patterns and subtle relationships in data and to infer rules that allow for the prediction of future results.”
Broadly speaking, there are two types of approaches based on which predictions are made from data. The first looks at patterns of activity that could be seen as indexical of more generalisable characteristics of extremist activity online. The second approach, in turn, has focused on identifying individual behaviour profiles of those who are potentially at risk of carrying out violent actions or radicalised into some form of extremist activity. Munk distinguishes these two approaches in the following way:
There are two practical analytics approaches to seeking to prevent terrorist attacks based on data. One is an inductive search for patterns in data, and the other is a deductive data search based on a model of criminal relations between suspicious persons, actions or things … methodologically, this distinction is called pattern-based data mining versus subject-based data mining … only pattern-based data mining constitutes proper predictive analytics in which outliner segments are inductively identified in a multi-dimensional universe – segments identified by the algorithm as deviant in a number of central variables in which the deviation is then connected with terrorism…. by contrast, subject-based data mining is merely traditional police investigation in a digitized form. No future predictions are involved, only the identification of a network of social relations.
This final blog post will thus focus on methods that aim (or claim) to predict behaviour based on past data. These algorithms are becoming increasingly important since the emergence of popular deep learning and AI-based approaches, which largely work through making such predictive inferences from previous data.
Overview of methods used in online extremism research
Most of the approaches currently in use in such predictive analyses rely on what is called supervised learning. This is a set of approaches where patterns in initial data (e.g. large-scale examples of extremist behaviour online or on social media manually labelled by researchers based on specific behaviour markers) is used to make predictions on previously unseen data granted that the initial data is sufficiently diverse so the model has learned all its relevant features.
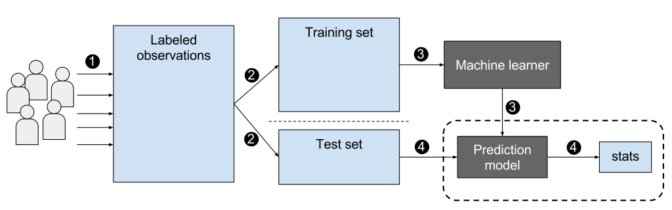
This is commonly done by dividing the labelled dataset into two different parts: the training set and the test set. This allows researchers to compare the training data with the test data to validate the predictive accuracy of the model in question (e.g. how well the results of the test set match the “ground truth” of the initial labelled training set). The assumption underlying this model is that, if the initial training set performs well on the test set, the model can then be used to predict future behaviour in new previously unseen data. Figure 1 shows the overall schematic workflow of supervised learning.
The second type of machine learning method used to predict behaviour – albeit not as commonly used in extremism research – is called unsupervised learning. Unlike supervised learning, this consists of machine learning approaches that try to learn patterns from data without having such prior “ground truth” to compare the results with. Instead of using previously labelled data, these approaches, therefore, try to learn features from the data. Because there is no prior knowledge to validate the results, unsupervised learning approaches depend more on the researchers’ interpretations of the relevance of the features that are found for further analysis (even if there are some statistical ways developed to validate the internal or external cohesion of the clusters or groups found). Figure 2 shows the unsupervised learning workflow.
Recent research has also used a mixed bag of other approaches, which, for instance, combine both supervised and unsupervised learning (semi-supervised learning) to mitigate the problem of not having enough data to base accurate predictions on. Another set of methods, such as reinforcement learning, try to iteratively learn from the process based on the feedback they receive.
These various approaches are now widely used in online extremism research, with new approaches being published frequently. They have been used on various research problems around predicting extremist behaviour, such as identifying extremist actors or extremist content or trying to predict patterns of radicalisation from multivariate patterns found in large datasets. They are also widely used by social media companies to automatically flag, detect, and remove extremist content on social media platforms. As especially deep learning or AI-based systems become more sophisticated and mainstreamed, their use by researchers will become more commonplace alongside growth in computing power and new sophisticated algorithms.
Cost-benefit analysis
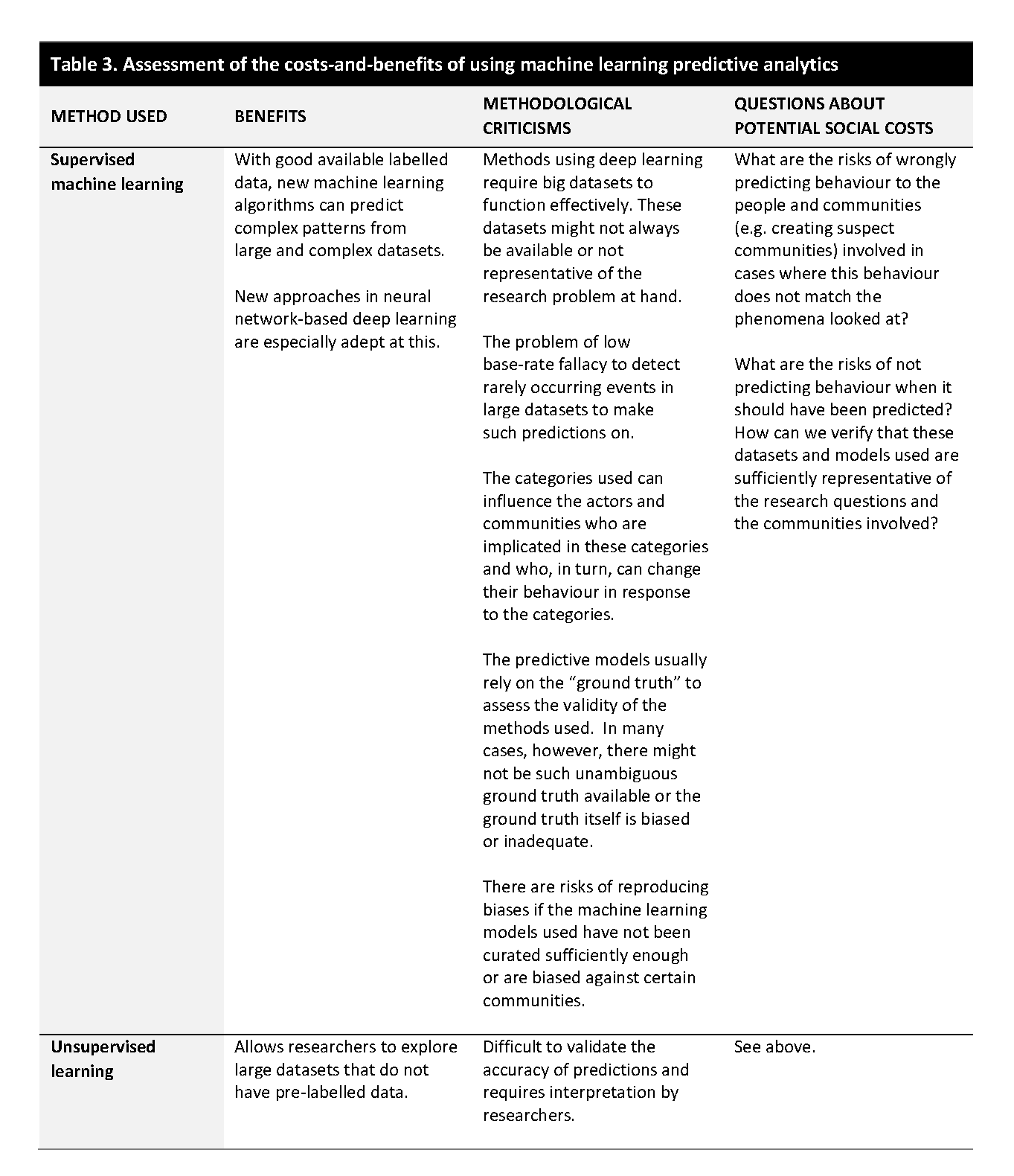
A critical analysis of all the different predictive models in circulation is of course impossible in a short blog post. There are, however, more specific criticisms raised about using machine learning- or deep learning-based methods to predict online extremist behaviour.
Some of the methodological criticisms include questions about the validity of the statistical models used for predictions. One of them is called the low base-rate fallacy, which illustrates the difficulty of predicting future behaviour, especially in instances where the behaviour looked at is rare. Munk writes that:
The underlying statistical premise for the value of the method is that society is a predictable, normally distributed, closed system. The statistical problem is that, like suicide, terrorism is a low-frequency event, and every single event can be seen as unique, which means that the risk of low base rate fallacy and over-generalization increases. Methodological generalization is impossible, as the amount of data is too small, and the result will always be underfitting or overfitting. Specifically, there is not enough data to build a model or to train the model to make a meaningful prediction. The problem is that there is no clearly defined pattern or statistical possibility of defining what can and must be seen as attempts, and failed attempts are often kept secret as an essential characteristic of criminal activity.
Another methodological problem raised deals more with the type of online and social media data used for such analysis and its representativeness. Tufekci, for instance, has identified four challenges in this:
- The first challenge involves the problem of using self-selected data from social media platforms without adequately addressing the structural constraints involved in how this data is produced (e.g. such as the over-reliance on public datasets on Twitter for online extremism research because this is easiest, and sometimes the only data, available).
- The second challenge involves problems of “choosing on the dependent variable” whereby the prediction made are derived from a self-selected sample of activity without taking into account its wider representativeness of broader social processes (e.g. such as understanding patterns of radicalisation online by looking exclusively at cases of violent extremism or terrorism where such examples of radicalisation did occur but not situations where it did not lead to radicalisation).
- The third challenge involves using vague, unclear or unrepresentative sampling of activity from online datasets (e.g. researchers only have access to data from people who regularly interact online and on social media but not those who do not leave public traces of their activity behind even if they may be more relevant for the research).
- Finally, the fourth challenge involves using data primarily from single platforms without taking into account the interconnectedness of contemporary online milieu, the multiplicity of interactions across different hybrid media platforms or the online-offline interactions of users (e.g. how does content spread across and through different platforms and how these practices online influence activities offline).
Another critical point raised involves the recursive relationship social science and humanities researchers have with the people they study, or what has been called, in more philosophical terms, the ‘double hermeneutic’ of social sciences. What this means is that the people who are studied are not passive subjects. Rather, they are “able to reflect on the rules applied” to their behaviour. Thus, as technology companies, governments, and researchers use different methods to predict activity online to take action based on these predictions, the people who are implicated in this process adapt their behaviour rendering the earlier predictions invalid.
One example of this would be how ISIS, in response to crackdowns on public social media use, has migrated to new platforms such as Telegram and other encrypted channels, which are not as amenable to the use of computational methods and large-scale data collection. Similarly, as online tactics by the extreme far-right have become more widely known, these groups have also modified their communicative approaches – in effect, to ‘hack’ the system – such as changing the ways they use offensive or racist language to avoid automated filtering and detection.
Such predictive methods have also been criticised for their potential social costs. One criticism raised is that such computational or big data approaches create static categories based on which individual behaviour is profiled and predicted online. Critical researchers have noted that research, however, has not been able to identify consistent psychological or behaviour profiles that would allow the reductionist classification of people based on the type of activity they exhibit online. On the contrary, such static categories risk creating feedback loops whereby – as the systems concomitantly learn from the increased availability of data based on this categorisation – the likelihood of the methods used to detect the behaviour will grow even if the risk, in reality, has not increased.
In the end, such predictive models only work as well as how accurate the “ground truth” applied to these models is. Without sufficient data, the predictions fail. However, as research has shown, there are also many situations where such “ground truth” perhaps does not exist, at least in a trivial or non-problematic way. One example of this would be situations of escalating conflict where antagonistic groups start to frame the core issues in fundamentally incommensurable ways. Especially in research focusing on sensitive social or political phenomena, this can make “objective” assessment of “ground truth” by researchers challenging, if not, at times, impossible. Llanso writes that:
approaches to addressing error in machine-learning systems, moreover, are fundamentally different from due process protections aimed at ensuring a just result. Machine-learning tools can be evaluated on their “accuracy,” but “accuracy” in this sense typically refers to the rate at which the tool’s evaluation of content matches a human’s evaluation of the same content. This kind of analysis does not address whether the human evaluation of the content is correct— “accuracy”, in this context, does not reflect assessment of ground truth.
Moreover, if the ground truth is inaccurate, it can become sedimented as the “truth” that subsequent research is based on, thus risking further marginalising vulnerable communities especially if the data is biased against them. One possible way forward to mitigate these challenges would, again, be to bring in more mixed methods or qualitative approaches to help better curate and assess the ground truth based on which predictive models are trained on. This also ultimately involves making sure that the modes used for analysis are as unbiased as possible to avoid exacerbating latent social or political biases in them.
More fundamentally, however, behind such predictive models is the philosophical assumption that patterns found in past data can be, or should be, projected onto future behaviour. This presupposes a quasi-deterministic universe where the future is seen as being somehow already present in the data in a sufficiently determinable form. Given the philosophical problems involved in “predicting the future”, critical researchers have noted that such predictive models perhaps do not help us predict this future as much as they help us understand how the imagined risks of this future are anticipated in such present data practices – and the contested politics involved in trying to manage the social and political threats of these future imaginaries.
Ultimately, it is good to note that in a field of research such as online extremism, the motivation behind predicting behaviour often involves not only understanding this phenomenon but also trying to find ways to prevent it, regardless of what the data or the models are. Academic literature on the topic similarly often tries to “model this process towards violence, such that it can be understood, predicted and acted upon” even if there might be other equally suitable, or more valid, methodological approaches available.
Therefore, the costs and benefits associated with such predictive methods cannot perhaps be assessed solely by the internal characteristics of the methods used, but must also include the wider horizon of their societal and political uses as well. One possible way to use these models, then, is to research what the use of these computational methods, and AI, in particular, can tell us more broadly about this future horizon of digital communication and the changing use of technology for mitigating the costs and benefits of this future.
Matti Pohjonen is a Researcher for a Finnish Academy-funded project on Digital Media Platforms and Social Accountability (MAPS) as well as a VOX-Pol Fellow. He works at the intersection of digital anthropology, philosophy and data science. On Twitter @objetpetitm.
Previously in the Series:
Part I: A Framework for Researchers
Part II: Identifying Extremist Networks
Part III: Analysing Extremist Content