
This series of four blog posts builds on discussions had during the ‘Inside the Black Box of “Terrorism Informatics”: A Cost-benefit Analysis of Using Computational Techniques in Violent Online Political Extremism Research’ workshop organised by VOX-Pol in 2018. [Ed.]
By Matti Pohjonen
One of the most pressing challenges in research on violent online extremism is how to accurately identify content that is representative of extremist activity found online, especially on social media. This challenge is exacerbated by the sheer volume of data generated on any given day, which has made the manual identification, collection, and analysis of this content largely infeasible. Computational methods are therefore oftentimes needed to make sense of the proliferation of what some scholars have called ‘digital traces’, the everyday data streams generated by our activity in online environments.
In response to this ‘big data’ research challenge, a host of new research methods have emerged that draw from, among others, social network analysis (SNA), data mining, natural language processing (NLP), computer vision and, more recently, machine learning, deep learning, and artificial intelligence (AI). Alongside their growing popularity, critics have also begun to voice concerns about questions of validity and ethics involved in using these methods. This concern has been amplified by the controversies around the use of personal data for political micro-targeting during the 2020 American presidential election, the use of predictive analytics in counter-terrorism, border control and policing or questions of bias in machine learning and AI-based models used for content moderation.
Many of these state-of-the-art approaches also require large datasets to be implemented effectively. There are usually three ways such data can be accessed from social media: platform-sanctioned open data, commercially available social media data, and unsanctioned open data. Commonly, academic researchers have relied on platform-sanctioned public data usually available through the application programming interfaces (API) of social media platforms.
Access to these open data streams has been increasingly throttled in the past few years due to concerns over the misuse of personal data and privacy, however. This rarefaction of openly available data, combined with the social media companies’ growing assertiveness in cracking down on extremist content online, has also brought with it new challenges for researchers hoping to use such computational or big data methods in new “data-poor research environments.” The exception is Twitter, which as of January 2021, has granted academic researchers improved free access to their data.
Computational or big data methods have a long history in extremism research, ranging from earlier work using social network analysis to identify ‘dark’ terrorist networks to more contemporary uses of machine and deep learning to predict extremist activity from multimodal patterns found in heterogenous online and social media data. The plethora of methods falling under this category has been sometimes described under the umbrella term of ‘terrorism informatics’ even if this term has been recently replaced by various other terms such as ‘computational’ or ‘digital’ methods.
Despite this fairly lengthy history, there is still little systematic knowledge available to assist researchers independently assess the costs and benefits of using such methods in different research situations. This series of three blog posts addresses this problem by using accessible non-technical language to explore some of the variety of approaches now available to researchers. The blog posts are divided into three parts, each focusing on different challenges in online extremism research:
- Identifying extremist networks
The first blog post describes and discusses research that has used social network analysis to gain insight into the actors, networks, and communities behind violent extremist activity online. Working with techniques from network analysis and graph theory, researchers have been able to gain new insights into questions about the nature of extremist networks and communities online: how such communities are formed, how they change over time and who are the central and influential actors in them. This also includes research that has explored the dynamics of information diffusion in networks (e.g. how, for instance, mis/disinformation spreads over time) or the use of agent-based modelling to model extremist activity (e.g. such as simulating the hypothetical effects of removing extremist actors on the evolution of the network). - Analysing extremist content
The second blog post explores approaches to extrapolating insights from online content such as posts, comments, images, or video. The techniques used for this purpose have historically involved natural language processing (NLP) techniques to explore patterns, topics, or the sentiment of textual content. Advances in computer vision and multimodal analysis have also recently made the analysis of images, video, and audio increasingly feasible for extremism researchers. - Predicting extremist behaviour
Finally, the third post focuses on approaches to predicting extremist activity from online or social media data. These approaches have generally focused on two types of indicators on which some type of predictive analysis can be done. The first explores aggregate patterns of activity that could be seen as indexical of more generalisable patterns of extremist activity online. The second involves research that has focused on developing risk profiles that allow researchers to predict what types of actors (or the communities they are associated with) are at high risk of carrying out extremist activity or being radicalised.
As the blog posts show, this categorisation of research into these three different types of methods is, of course, to some degree arbitrary. Research looking for predictive patterns of online extremism can often combine multiple categories into its research framework, including the social networks and the content produced in them. Similarly, state-of-the-art methods in deep learning and AI often excel in analysing multivariate relationships using heterogeneous data thus further blurring the boundaries between the different categories used.
The blog posts will nevertheless use these categories as a kind of working heuristic to explore some of the popular methods used by researchers. They are thus not meant to provide a conclusive account of all the new computational approaches in use in extremism-related research or to even attempt the Sisyphean task of keeping track of all the rapid advancements in, especially, machine/deep learning and AI. Rather, the aim is more humble: to provide researchers with some background knowledge that can hopefully help, especially non-technical, researchers independently assess the costs and benefits of using these methods in their own research.
Cost-benefit framework for analysis
When assessing the costs and benefits of using these methods in different research situations, the blog series highlights two types of questions relating to the use of computational or big data methods:
- How valid are these methods for identifying representative extremist content or actors online, including on social media? What are some of the methodological criticisms involving their use?
- What are some of the potential adverse direct or indirect social effects involved in using them? What are some of the broader questions of ethics raised by them?
Underlying the cost-benefit framework is a broader assumption that one of the biggest challenges in online extremism research, especially when working with large-scale public data, has to do with the question of how to identify data that is representative of the phenomena in question. This raises the subsidiary question of how, then, when deciding on the possible use of different methods, should researchers take into account this delicate balance between questions of validity (e.g. selecting the methods that help find a sample that is relevant to the research questions) while minimising the social harm of getting things wrong (e.g. unfairly targeting individuals and communities through the overzealous use of computational methods)?
To systematically address this research trade-off, this series of posts highlights what has been called in the scientific lexicon the false positive/false negative trade-off. In other words, the challenge of accurately identifying representative data can be approached through what is called the confusion matrix. This is a research heuristic that has been developed to systematically explore the consequences of getting things right versus getting things wrong.
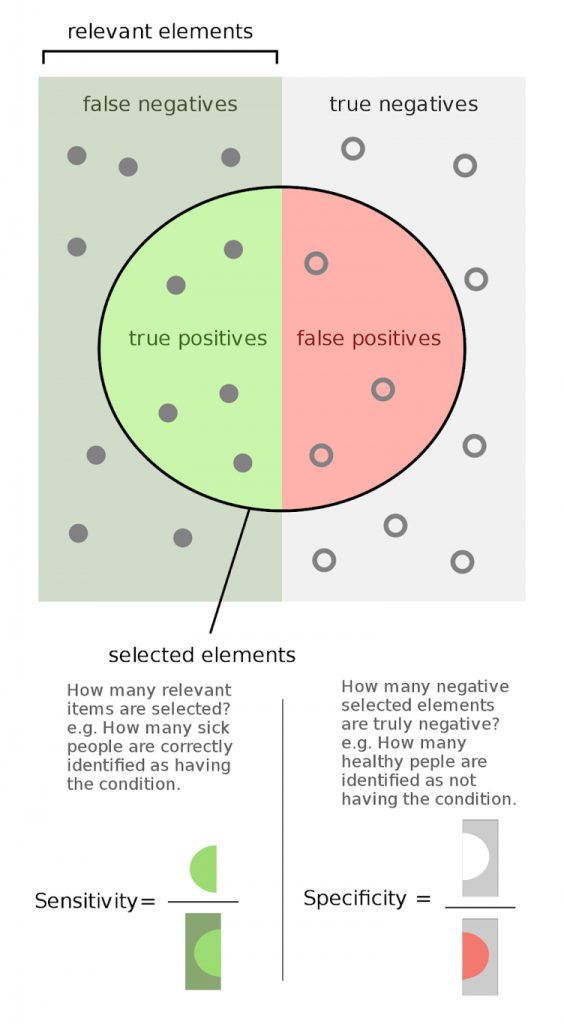
A confusion matrix can have four outcomes depending on how accurately the research identifies the phenomena in question. The first two categories, true positives and true negatives, are unproblematic as they accurately identify the phenomena in question. The two other categories, false positives and false negatives pose more challenges for research. This is because false positives involve situations where a phenomenon is falsely identified as belonging to a category when this is not the case. False negatives, in turn, include situations where the phenomenon is falsely not identified as belonging to a category when it clearly should have been included in it.
What is crucial to further note about this confusion matrix (especially for social science researchers who might not be as familiar with it) is that the optimal trade-off between false positives and false negatives cannot be decided through technical or methodological considerations alone. Rather, this decision where the optimal trade-off (e.g. between so-called Type 1 and Type 2 errors) is delineated has to inevitably include factors that are external to the research methods used. In the more scientific lexicon, again, this involves making a decision between sensitivity and specificity of the methods used.
A classical example would be medical research. The cost of falsely identifying a patient with a disease (false positive) can have negative repercussions if expensive medication with strong side-effects is administered for a non-existent disease. Conversely, not accurately identifying a patient with a disease (false negative) can also have negative repercussions as the disease can go untreated resulting in harm or even death. In an imperfect world where no system has 100% accuracy, where this trade-off between false positives and false negatives is decided (e.g. giving patients expensive medicine without reason versus not identifying the disease) has to include considerations that are external to the methodology used.
Similarly, when looking at the costs and benefits of using different computational or big data methods in online extremism research, such methodological decisions need to also involve such normative-ethical deliberations that are external to the research methods used. On the one hand, falsely identifying actors or communities as ‘violent extremist’ can have negative repercussions if the performative act of research, for instance, risks creating “suspect communities” where the prevalence of violent extremism identified by the research does not match actual social reality. On the other hand, not accurately identifying relevant actors or communities as ‘violent extremists’ can also have negative repercussions, for instance, in situations where the harm of violent extremism could have been mitigated but was not because the methods used were not appropriate or the ethical considerations too restrictive.
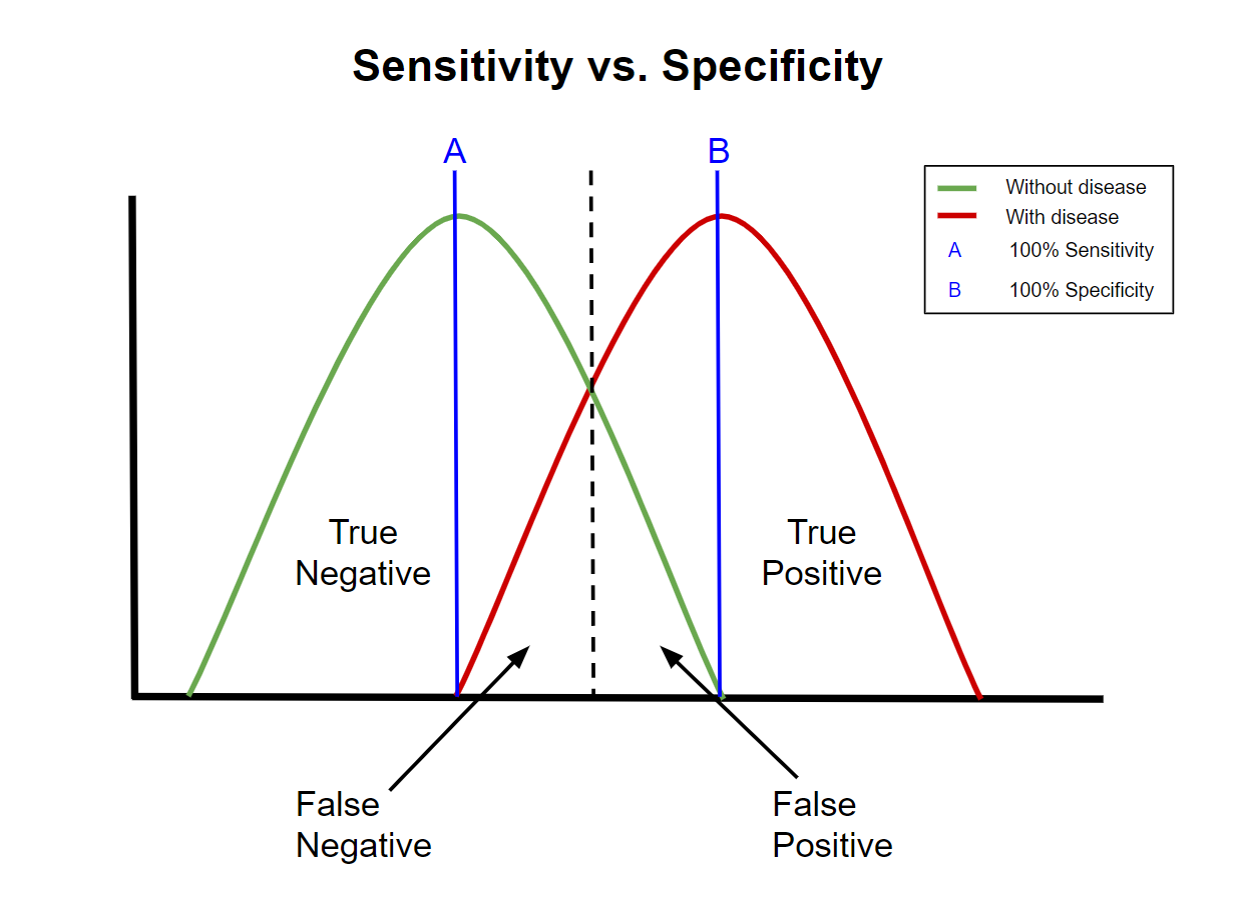
The next three blog posts will thus argue that such methodological considerations need to include an understanding of this trade-off between the benefits derived from using different methods and the negative externalities of using them. This inevitably involves a normative-ethical decision regarding where this cut-off point between questions of security (e.g. correctly identifying violent extremists to prevent violent attacks or their social harm) and privacy/personal liberty (e.g. the social and privacy harm of misidentifying individuals and communities as extremist) is drawn, not only in research situations but perhaps in a democratic society more generally. (H/T Timme Bisgard Munk for drawing my attention to this point). The question of this optimal trade-off can never be fully solved in an imperfect world. It is ultimately a more fundamental question that the blog posts do not claim to resolve.
Finally, it is also important to note that having adequate access to data for computational analyses remains an ongoing challenge for researchers. Without sufficient data, deciding what methods to use in research, is a moot point. Ultimately, despite the challenges outlined in the blog posts, independent academic researchers are nonetheless best placed to assess what the costs and benefits of these methods are; a task that is too important to leave fully in the hands of companies or governments.
Matti Pohjonen is a Researcher for a Finnish Academy-funded project on Digital Media Platforms and Social Accountability (MAPS) as well as a VOX-Pol Fellow. He works at the intersection of digital anthropology, philosophy and data science. On Twitter @objetpetitm.
Next in the series:
Part II: Identifying Extremist Networks
Part III: Analysing Extremist Content
Part IV: Predicting Extremist Behaviour