
By Sam Jackson
For years, researchers studying online political extremism have used computational tools to collect large amounts of data from social media, most often from Twitter. Two main logics guide these data collections: they can be built around users (e.g., collecting all tweets sent by given accounts) or they can be built around vocabulary (e.g., collecting all tweets that contain certain terms, often in the form of hashtags). The second logic can be a particularly good strategy for researchers who are collecting data related to a particular form of extremism across time, especially if the community of users engaged with that form of extremism changes over time. For example, researchers interested in studying the so-called “alt-right” can use collection terms (perhaps “alt-right” and “Pepe”) to gather data from influential figures in the movement (like Richard Spencer) and from less well-known individuals who might move in and out of the movement.
This logic of data collection has one major limitation, though: it (often) uses a fixed list of collection terms, which means it doesn’t take into account shifts in language. There are three reasons why researchers should account for shifting language when collecting data. First, the specific things that communities (whether extremist or not) talk about change over time. For example, ISIS supporters talk about some things consistently over time (like the caliphate), but other topics wax and wane (like specific attacks carried out by the group’s supporters).
Second, the language that communities use to talk about the same thing changes over time. For example, supporters of the racist right in America have used different terms at different times to refer to the same cluster of ideas: white supremacy became white nationalism (and white separatism), which became the “alt-right.”
Third, extremist communities have an incentive to avoid detection, and one way they do this is by adopting rhetorical symbols (through codes and dog whistles, for example). Consider an offline example: the German far right long used “88” as a code for “Heil Hitler” (because “H” is the 8thletter of the alphabet). When some authorities included “88” in a list of banned references to the Nazi Party, the far right shifted the code to become “100-12.”
Each of these kinds of shifts in language can happen gradually or suddenly. Either way, data collection strategies built around fixed collection terms are unlikely to catch the changes, leading researchers to miss data they might be interested in. Researchers can account for shifting language by exploring the data being collected on a regular basis, but this can consume a lot of time.
To help researchers account for shifting language, I developed an open-source tool called FlockWatch that monitors textual data collections for shifting language automatically, suggesting new terms that researchers might want to use to collect data. It does this in two ways. First, it looks for trending words (i.e., those that are being used more frequently over time) in the dataset. Second, it looks for words that often appear alongside the collection terms. Paying attention to trending words lets FlockWatch pick up on new topics (the first reason that language might shift); paying attention to co-occurring words lets FlockWatch pick up on gradual shifts in language about the same topics (the second and third reasons that language might shift).
To find these trending and co-occurring terms, FlockWatch uses data containing two pieces of information: the text of a message and when that message was created. FlockWatch creates two sets of messages – each corresponding to a different period of time – that it will compare to each other. The text of the message is where FlockWatch does its main work, taking a “bag of words“ approach to look for trending words and word that co-occur with existing collection terms.
FlockWatch is not itself a data collection too. It’s meant to supplement other tools that collect data. By default, it knows how to work with a Twitter data collection tool called STACK, knowing where to find information about message text and message creation date. It can also analyze data from a CSV. This flexibility allows researchers who use any tool to collect digital textual data from any source to use FlockWatch to improve their long-term data collection strategies.
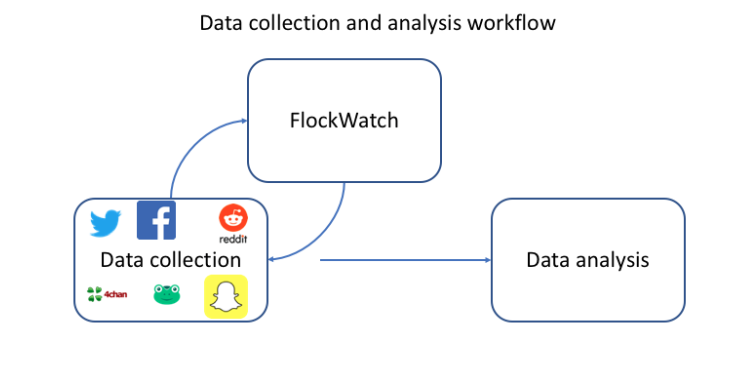
This tool is meant to complement data collection tools. Thinking about a research project workflow, FlockWatch is part of the data collection process. Especially for long-term data collection, users should plan to use FlockWatch repeatedly – sending data to the tool, using its output to modify the data collection strategy, collecting more data, sending that new data to the tool, and so on.
FlockWatch functions by analyzing the text in datasets, so it is no surprise that it is useful for researchers conducting textual analysis. It is also useful for research analyzing other types of data (for example, social media user networks or multimedia use) by helping them build richer, more comprehensive datasets: network studies of how conspiracy theories spread through Twitter, for example, are better if they are based on a broader portion of messages about conspiracy theories.
Importantly, FlockWatch does not make any decisions about which trending or co-occurring terms should be used as additional collection terms. It gathers information about these terms, then presents that information to the user so that the user can decide which terms to use.
It’s also important to note that FlockWatch will work better for some topics than for others. Right now, FlockWatch only monitors text for shifts in individual words – it doesn’t pay attention to phrases (not least because of the computational cost that would be required to monitor phrases). This means that it is likely that FlockWatch will be more helpful for broader collections than for more focused collections. I have been using two different Twitter data collections to test FlockWatch, and these collections illustrate this limitation.
The first collection is focused on conspiracy theories in the U.S., originally built using “qanon” and “pizzagate” as collection terms. FlockWatch output led me to add “whoisq”, “sethrich”, “qisback”, “wwg”, “1wga”, “pedowood”, “qarmy”, “pedogate”, and “wwg1wga.” After several days, 28% of all tweets collected after adding these additional collection terms (83,238 out of 297,336) did not contain the original collection terms. In other words, FlockWatch helped me collect nearly 40% more tweets in a 2 week period.
The other collection is focused on MS-13, a criminal gang that some Americans believe is responsible for extensive violence in the States and has been a focus for anti-immigrant activists. The original collection terms for this dataset were “MS-13” and “MS13.” This is a much more focused dataset, and after five days, I only chose one term that FlockWatch had recommended to use as an additional collection term (“evilsanctuarycities”). After four days, this additional collection term had not appeared in a single tweet collected after adding the new term.
I suspect that phrases rather than words would be more useful for this dataset, as few individual words are specific enough for me to be confident that they are related to MS-13 specifically. For example, FlockWatch might recommend “border” for this collection, but “border” is used in too many contexts for it to be a good collection term (other geographical borders, the border of someone’s lawn, the border of a bulletin board, etc.). FlockWatch might also recommend “wall,” but this word also has too many meanings to be useful as a collection term. “Border wall” is a better collection term for this dataset, but even this phrase is not specific enough to truly focus on conversation about MS-13. For the time being, FlockWatch is likely to struggle to recommend useful terms for very specific collections like this one.
FlockWatch is meant to be flexible. It can be run on different operating systems including Windows, MacOS, and Ubuntu. It can also run on text in any language, but those using non-English text will need to go without stopwords or provide their own list. It can run on data from any source, as long as there is a timestamp associated with the text. It’s even possible that FlockWatch could be useful for longer texts (like magazine articles or blog posts), but I haven’t tested it on those types of text.
I hope that other researchers will find that FlockWatch is a useful tool for building more comprehensive datasets from sources like Twitter, though it will not always help. Ultimately, nothing can replace a researcher’s expertise in selecting criteria around which to collect data. FlockWatch is meant to help researchers use their expertise in a targeted way, not replace their judgment. Particularly for those of us who build large, long-term collections of social media data, this kind of tool can streamline efforts to gather good data, allowing us to spend more time on other parts of the research process.
Sam Jackson is assistant professor at the University at Albany’s College of Emergency Preparedness, Homeland Security and Cybersecurity. You can follow him on Twitter: @sjacks26