
By Ryan Scrivens
There’s been a shift in recent years in how researchers investigate online communities, whether it’s the study of how extremists communicate through social media or analysis of users connecting through online health forums. In particular, scholars who do this work are shifting from manual identification of specific online content to algorithmic techniques to do similar yet larger-scale tasks. This is a symptom of the ‘Big Data’ phenomenon – i.e. a massive increase in the amount of data that is readily available, particularly online.
It’s become increasingly difficult – nearly impossible even – to conduct a thorough manual search for content on the Web because it contains such an overwhelming amount of information. In response to this growing challenge, a number of scholars have incorporated machine learning techniques into their research designs.
I am fortunate enough to be part of this growing trend in the field of terrorism and extremism studies. For the last two years, I have collaborated with my PhD Senior Supervisor, Dr. Richard Frank from the School of Criminology at Simon Fraser University (SFU), on a number of projects that use machine learning tools to analyze radical content online, including but not limited to the identification of relevant pieces of text on extremist-based websites and discussion forums. My background is in criminology and Richard’s is in computer sciences, which to some may seem like a strange duo, but we draw from each other’s strengths: Richard works on the technical components of a project (e.g. developing, modifying and/or applying a range of technologies to the data), and I generally frame the research question(s), analyze the data, and situate our research within the broader literature. We are not the only ones to conduct research in this manner. In fact, many others have embraced this collaborative approach, including members of VOX-Pol.
In 2015, Richard re-connected with VOX-Pol’s Co-ordinator, Dublin City University’s (DCU) Prof. Maura Conway, at an intelligence and security informatics conference in Paris, and they chatted about their most current research project. Richard mentioned that for my dissertation, I was in the process of analyzing a sub-set of the notorious white supremacy forum, Stormfront, via a machine learning approach. Maura mentioned that one of VOX-Pol’s initiatives was to analyze online far-right content and activity; she thus suggested that I apply for the network’s Researcher Mobility Programme, perhaps working with computer scientists in Dublin.
Thrilled by this potential opportunity, I submitted an application and, later that year I was accepted for a three-month internship with VOX-Pol, collaborating with machine learning specialists Prof. Pádraig Cunningham, Dr. Derek Green, and PhD student Tania Malik at University College Dublin’s (UCD) School of Computer Science. The general task would be to explore online political extremism using advanced computational techniques, and the purpose of the undertaking would be to enhance some of the machine learning tools that VOX-Pol were developing.
On arrival in Dublin, I learned of VOX-Pol’s Lexicon Interface and that the research team were very much interested in assessing its capabilities. My task, then, was to work with them to identify the strengths and limitations of the interface, essentially making it more user-friendly for social scientists. This would require that I first select a topic of study and data that reflected an important gap in the literature, as well as construct a set of feasible research questions.
An exhaustive review of the literature revealed that academics have paid considerable attention to why right-wing extremists – and extremists in general – communicate online, with methods of analysis ranging from the traditional in-depth qualitative approach to a macro-level machine learning approach. Much of this research, however, has focused on why male users communicate with one another, largely ignoring female user activity. Thus, we decided to focus on the online discussions of the women in the movement, a unique avenue to explore which was through For Stormfront Ladies Only, a Stormfront sub-forum restricted to (those claiming to be) females.
Of the many tools that the interface had to offer, we tested the lexicon builder using the following data: 48,565 postings by 3,275 authors, dating from 2007 to 2015. Here the lexicon generation process was fairly straightforward and could be applied to virtually any dataset: (1) data was extracted by a web-crawler and uploaded to the interface (Step I.); (2) seed words were manually selected by the user and added to the interface (Step II.); (3) seed words were analyzed by the word2vec lexicon builder (i.e., the Mikolov C version), which retrieved a list of words in the data that were closely related to the seed words and were based on word frequencies in the vector space (Step III.A); (4) with the selected list of words (i.e., the lexicon), authors who used the retrieved words were assigned with a word intensity score [(#lexicon_words) /(total_document_words)] (Step III.B), thus creating word intensity lexicons for a particular topic (Step IV.). Intensity values could also be aggregated into time points (e.g., months), which produced word intensity lexicons over time (Step V.) (see Figure 1).
Figure 1. Data Collection and Lexicon Generation Process
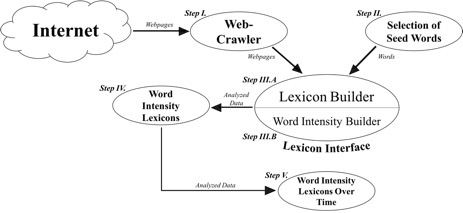
Overall, the purpose of this technique was to develop a number of lexicons with a select number of keywords that were linked to the topics of interest (i.e. those relating to right-wing extremism, such as victims of hatred, for example), and then use the lexicon builder to find other relevant words – based on the patterns that word2vec uncovered in the data – to expand the seed set of words, thus generating a larger list for future analysis. Topic-specific lists were then run through the word intensity classifier, which produced word intensity values for each author in the sample. Through this interactive technique, we explored a number of research questions that were of interest to both social scientists and computer scientists.
From a computer sciences perspective, two key findings emerged. First, results suggested that the word2vec algorithm could retrieve a meaningful list of keywords that, in turn, provided an understanding of the topics of discussions; word2vec operated as a “context finder” on issues relating to ladies of the far-right. Second, word2vec served as search and retrieval tool where, trained properly, could identify a small group authors within a much larger sample authors who discussed a particular topic of interest.
From a social sciences perspective, results suggested that the largest proportion of discussions in the sub-forum were “female-related,” including those that were associated with ‘women,’ ‘men’, and ‘family,’ followed closely by discussions on ‘Blacks.’ While the majority of the discussions intensified at a moderate rate over time, discussions on ‘Blacks’ intensified at the highest rate in the sample (see Figure 2).
Figure 2. Average Word Intensity Value per Time Point for Discussions on ‘Blacks’
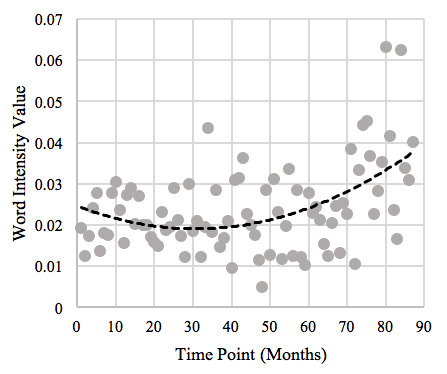
These findings didn’t come as a surprise, given that previous studies indicate that Stormfront sub-forum discussions tend to focus on threats of miscegenation and transracial heterosexual contact, particularly between white women and black men. Surprising, however, is that a large proportion of the authors in the sample use a small list of slur-words to describe members of the black community. Previous research, on the other hand, suggests that a reason for Stormfront’s longevity is its ability to circumvent and even discourage blatant discrimination; site moderators promote subtle and cryptic forms of hatred. Nevertheless, while these inconsistencies deserve further investigation, they may be a symptom of the methods that were employed in the current study and previous studies (i.e. a machine learning approach and qualitative approaches, respectively). The machine learning approach did, in fact, reveal the broad extend of the slur-terms in the sub-forum.
In response to the flood of information on the Web, many of those who study extremist content online – whether it involves the investigation of the far-right or other forms of extremism – have done so using machine learning tools. Working with VOX-Pol computer scientists has enabled me to be a part of this growing body of knowledge. Together we drew from each other’s strengths and overcame the challenges of conducting such novel research. During this process, we discovered that the lexicon builder, particularly its search and retrieval application and its context finder, was a promising tool for future research endeavours. Future studies will indeed thrive from this machine learning technique, one that was enhanced by bridging computer sciences and social sciences.
Ryan Scrivens is a PhD Student in the School of Criminology at Simon Fraser University (SFU), Canada and a Research Associate with the International CyberCrime Research Centre (ICCRC). Ryan is also the Coordinator of the Canadian Network of PhD Theses Writers for the Terrorism Research Initiative (TRI) and a member of the VOX-Pol Network of Excellence. His primary research interests include right-wing extremism, extremists’ use of the Internet, research methods and methodology, and classification.